

全球大模型评测金标准LMSYS榜单:国产黑马与GPT4o并列中文榜冠军
发布时间:2024-05-23 14:28:46 | 来源:千龙网 | 作者: | 责任编辑:科学频道
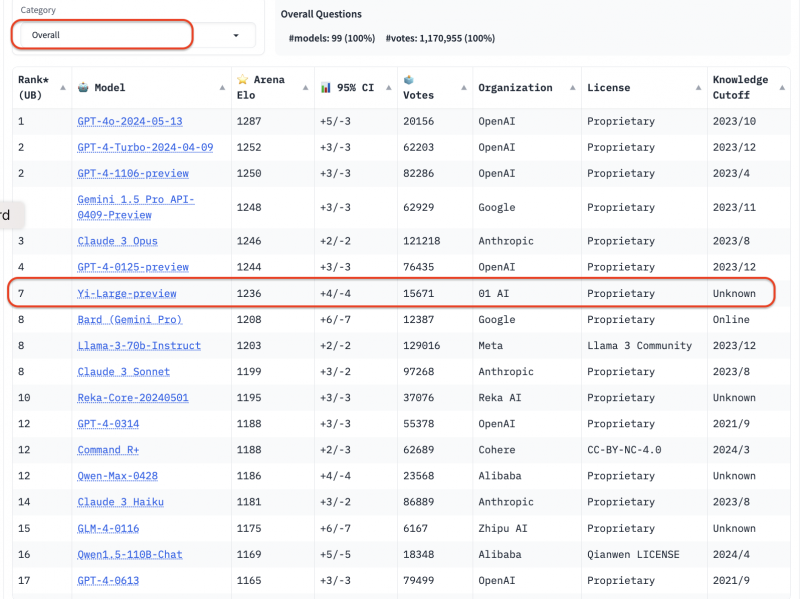
5月20日,被誉为全球大模型评测金标准的大模型竞技场LMSYS Chatbot Arena发布了最近盲测排名。在此次排名中,来自零一万物的最新千亿参数模型 Yi-Large总榜排名世界模型第7,中国大模型中第一,已经超过Llama-3-70B、Claude 3 Sonnet。
零一万物也由此成为了总榜上唯一一个自家模型进入排名前十的中国大模型企业。在总榜上,GPT系列占了前10的4个,以机构排序,零一万物 01.AI仅次于 OpenAI, Google, Anthropic之后,以开放金标准正式进击国际顶级大模型企业阵营。
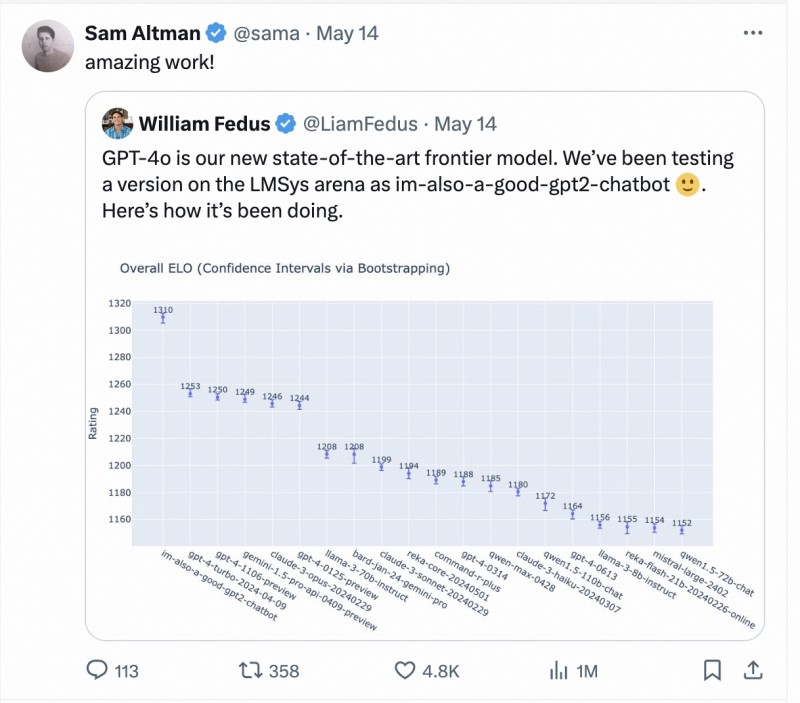
在前一周,类似黑马事件也曾上演。一个名为“im-also-a-good-gpt2-chatbot”的神秘模型现身Chatbot Arena,排名直接超过GPT-4-Turbo、Gemini 1.5 Pro、Claude 3 0pus、Llama-3-70b等各国际大厂的当家基座模型。随后OpenAI揭开“im-also-a-good-gpt2-chatbot”神秘面纱——正是GPT-4o的测试版本,OpenAI CEO Sam Altman也在Gpt-4o发布后亲自转帖引用 LMSYS arena盲测擂台的测试结果。
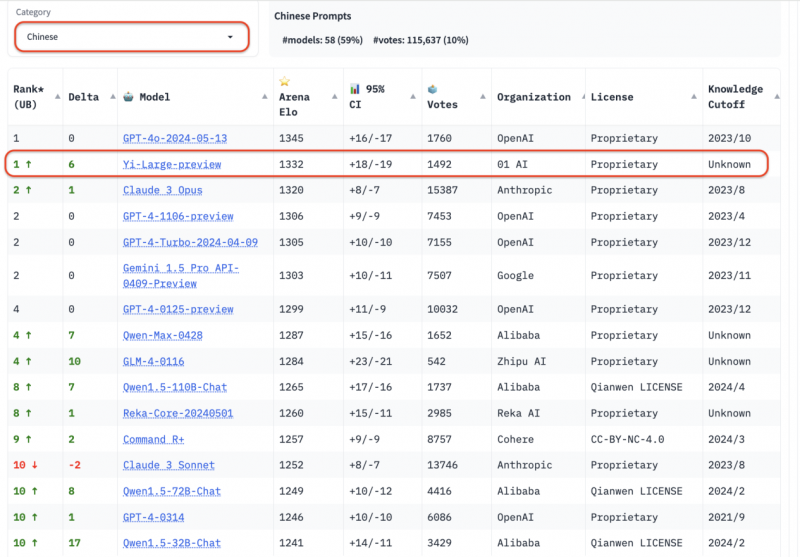
值得一提的是,在总榜之外,LMSYS的语言类别上新增了英语、中文、法文三种语言评测,开始注重全球大模型的多样性。在本次 LMSYS盲测竞技场最新排名的中文分榜中,零一万物的最新千亿参数模型 Yi-Large拔得头筹,与OpenAI官宣才一周的地表最强 GPT4o GPT4o并列世界第一。
国内大模型厂商中,智谱GLM4、阿里Qwen Max、Qwen 1.5、零一万物Yi-Large、Yi-34B-chat也参与了此次盲测,其中,Qwen-Max和 GLM-4在中文榜上也都表现不凡,分别位列第12位和第15位。
作为由开放研究组织 LMSYS Org(Large Model Systems Organization)发布的一种评测方法,LMSYS盲测在全球范围被普遍用来评估模型的性能,并通过平台随机比试与匿名的众筹线上盲测评选,测评结果受到OpenAI、Anthropic、Google、Meta等国际大厂的认可。
无论是出于自身模型能力迭代的考虑,还是立足于长期口碑的视角,大模型厂商应当积极参与到像Chatbot Arena这样的权威评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。